Just in case you’re wondering, I do have some legitimate excuses for taking so long to write and post this. It’s been a pretty crazy few weeks, thanks to a sixteen-day-long sinus infection, (it seemed like a lot longer than that) the demise of my car, and just general life/work things. But I had this blog post almost ready to go two weeks ago, so it’d be silly to just scrap it. So at this point, I’m just posting what I’ve got; I apologize if it’s a little disorganized and inadequately edited.
 I’d like to start by pointing out that we are slowly getting closer to living in a universe where Star Trek technology is a reality. Unfortunately, this isn’t about transporter beams. (Although I’ll come back to that in a few paragraphs) It’s about cloaking devices, which isn’t even Earth technology; hence my choice to use a picture of a Klingon space vessel. Although I’m most familiar with the original series, the internet informs me that the use of cloaking technology would violate the Treaty of Algeron, signed by the Federation and the Romulans in the year 2311. However, our 21st-century earth physicists have been indicating for a few years now that invisibility is plausible. This article, which is more than a year old, describes some of the more promising developments towards the goal of manipulating light waves to make things invisible. The article references Harry Potter instead of Star Trek, though, which is just silly because the invisibility cloak in Harry Potter is clearly magic.
I’d like to start by pointing out that we are slowly getting closer to living in a universe where Star Trek technology is a reality. Unfortunately, this isn’t about transporter beams. (Although I’ll come back to that in a few paragraphs) It’s about cloaking devices, which isn’t even Earth technology; hence my choice to use a picture of a Klingon space vessel. Although I’m most familiar with the original series, the internet informs me that the use of cloaking technology would violate the Treaty of Algeron, signed by the Federation and the Romulans in the year 2311. However, our 21st-century earth physicists have been indicating for a few years now that invisibility is plausible. This article, which is more than a year old, describes some of the more promising developments towards the goal of manipulating light waves to make things invisible. The article references Harry Potter instead of Star Trek, though, which is just silly because the invisibility cloak in Harry Potter is clearly magic.
This new article also mentions Harry Potter, although the technology that it describes is even less similar to a magical invisibility cloak. This time, instead of blocking light waves, the researchers are working on blocking water waves. It’s a little less exciting, maybe, but it has practical applications. Obviously, it’s useful for anything that has to do with boats. The article quotes one physicist as joking that their work will make it easier to have coffee on a boat, but I’m not sure that’s so much a “joke” as it is a worthy pursuit. What makes this development especially interesting, though, is that it essentially works the same way that a light-wave-blocking cloaking device would.
So what about the transporter beams I mentioned earlier? Well, as you probably realize, real Star-Trek-esque teleportation technology doesn’t exist and isn’t likely to reach us anytime soon. I only mention this development in the context of transporter beams because of this somewhat clickbaitish headline and the Star Trek references in the article. In actuality, this story is about communication and computer science. (In other words, it has more relevance to Uhura than to Scotty)
 Until now, quantum computers have used qubits, which is basically the same thing as a bit for regular computers. A bit is the smallest unit of computer information storage; it represents a single 0 or 1 in binary code. 8 bits make one byte, which is the amount of computer storage needed for a single letter, (or other character) and most computer files take up at least several hundred kilobytes, (aka KB) each of which is actually 1024 bytes. This random (but adorable) picture of my cat Melchizedek takes up over 102 KB on my computer; it’s 105,404 bytes, which is 843,232 bits. The point of all this is that a bit or qubit is a very small thing. Again, it stores one digit of binary code. The news story here is that now there’s such a thing as a qutrit, which stores a digit of ternary code instead of binary. While binary code has two possible values for each digit, ternary code has three possible values, and therefore, a qutrit is slightly bigger than a qubit or a bit.
Until now, quantum computers have used qubits, which is basically the same thing as a bit for regular computers. A bit is the smallest unit of computer information storage; it represents a single 0 or 1 in binary code. 8 bits make one byte, which is the amount of computer storage needed for a single letter, (or other character) and most computer files take up at least several hundred kilobytes, (aka KB) each of which is actually 1024 bytes. This random (but adorable) picture of my cat Melchizedek takes up over 102 KB on my computer; it’s 105,404 bytes, which is 843,232 bits. The point of all this is that a bit or qubit is a very small thing. Again, it stores one digit of binary code. The news story here is that now there’s such a thing as a qutrit, which stores a digit of ternary code instead of binary. While binary code has two possible values for each digit, ternary code has three possible values, and therefore, a qutrit is slightly bigger than a qubit or a bit.
I’ve just about run out of reasonable excuses for Star Trek references, but I do have a couple other things to share that have extraterrestrial subject matter. This first one stays pretty close to home. Astronomer David Kipping has suggested that we could make a giant telescope by essentially using the earth’s atmosphere as the lens. We’d just need a spaceship in the right place and equipped with the right devices; the refraction of the light is a natural phenomenon. You can see Kipping’s paper here.
 Meanwhile, five of Jupiter’s recently-discovered moons have been named. The names were chosen via an online contest, but the options were somewhat limited, since it has already been established that all of Jupiter’s moons must be named after figures from Greek or Roman mythology who were either lovers of Zeus/Jupiter or descended from him. (While there are some differences between the Greek and Roman myths besides the gods’ names, it’s still fair to consider Zeus and Jupiter to be essentially equivalent from an astronomical standpoint) These five moons each get their name from a Greek goddess who is either a daughter or granddaughter of Zeus. Their names are Pandia, Ersa, Eirene, Philophrosyne, and Eupheme. For a complete (and apparently up-to-date) list of moon names, click here. Just to be clear, the picture I’ve used here is Jupiter itself, not a moon.
Meanwhile, five of Jupiter’s recently-discovered moons have been named. The names were chosen via an online contest, but the options were somewhat limited, since it has already been established that all of Jupiter’s moons must be named after figures from Greek or Roman mythology who were either lovers of Zeus/Jupiter or descended from him. (While there are some differences between the Greek and Roman myths besides the gods’ names, it’s still fair to consider Zeus and Jupiter to be essentially equivalent from an astronomical standpoint) These five moons each get their name from a Greek goddess who is either a daughter or granddaughter of Zeus. Their names are Pandia, Ersa, Eirene, Philophrosyne, and Eupheme. For a complete (and apparently up-to-date) list of moon names, click here. Just to be clear, the picture I’ve used here is Jupiter itself, not a moon.
Moving on to a different scientific field, I’m happy to report that science has confirmed that chocolate is good for you, especially dark chocolate. This cross-sectional study of over 13,000 participants indicates that eating some dark chocolate every other day could reduce the likelihood of having depressive symptoms by 70 percent. (Google Docs put a squiggly line under the phrase “every other day” and suggests that I meant “every day”. Maybe Google knows something that the rest of us don’t.) In other nutritional news, the flavonoids found in apples and tea evidently lower the risk of cancer and heart disease. And this pilot study has suggested that pregnant women would do well to drink pomegranate juice or consume other foods high in polyphenols (a category of antioxidants) in order to protect their prenatal children from brain problems caused by IUGR, (intrauterine growth restriction) a very common health issue which often involves inadequate oxygen flow to the developing brain. A larger clinical trial is already underway.
A recent study indicates that there could be a genetic link between language development problems and childhood mental health problems. Educators have noted in  the past that kids with developmental language delays are often the same kids with emotional or behavioral problems, but as the article says, it’s always been generally assumed that the reason for this is causal; the idea is that the frustration or confusion that comes from language difficulties causes (or exacerbates) emotional issues. But this study used statistical analysis of participants’ genetic data to evaluate the correlation, and researchers think that both types of problems could be caused by the same genes.
the past that kids with developmental language delays are often the same kids with emotional or behavioral problems, but as the article says, it’s always been generally assumed that the reason for this is causal; the idea is that the frustration or confusion that comes from language difficulties causes (or exacerbates) emotional issues. But this study used statistical analysis of participants’ genetic data to evaluate the correlation, and researchers think that both types of problems could be caused by the same genes.
Interestingly enough, another potential cause of childhood mental health problems is strep throat. This article isn’t really new information; clinicians have been studying PANDAS (pediatric autoimmune neuropsychiatric disorder associated with streptococcal infections) for a couple decades, and there is still debate over what is actually going on in the patients’ brains, whether PANDAS should be considered a form of OCD or a separate disorder, and whether PANDAS is even a real thing. The article linked above describes one specific case and describes some of the questions and research.
Here’s another one about child development. A researcher in Australia developed a preschool program based entirely upon music and movement. The idea is that these kinds of activities are such effective tools in early childhood education that they can help to close the achievement gap between children from different socioeconomic situations. This is one of those cases where common knowledge is a little ahead of official scientific research. As a children’s librarian, I can verify that virtually anyone who works with kids knows that singing and dancing helps kids learn. There are several reasons for this, ranging from “it activates numerous brain regions at the same time, thereby forming connections that aid both memory and comprehension” to “it burns off excess energy and keeps the kids out of trouble”. For these and other reasons, most preschool programs (and, of course, library storytimes) involve a lot of songs, most of which have their own dances or hand movements. Besides that, school-age kids who take classes in music and/or dance tend to be more academically successful than those who don’t. As far as I know, nobody has ever done the research to officially confirm that, but lots of people in education and the arts are aware of it. (If there’s anyone reading this who has the academic background and the means to do such a study, I’d like to request that you pursue that. Please and thank you.)
 The next two studies I want to mention are so closely related in their subject matter and findings that I initially thought that these two articles are about the same study. But they aren’t. Although they both involved using MRI technology to watch what someone’s brain does while they read, this one from scientists in England was looking at how the brain translates markings on paper into meaningful words, while this study from the University of California, Berkley compared the brain activity in subjects who read and listened to specific stories. The most conclusive finding from that particular study was that, from a neurological perspective, listening to audiobooks or podcasts is essentially equivalent to reading with your eyes, which almost seems to contradict the England study, which obviously showed that visual processing is the first neurological step in reading. That’s not really a contradiction, though, when you stop to think about just how busy the brain is when reading.
The next two studies I want to mention are so closely related in their subject matter and findings that I initially thought that these two articles are about the same study. But they aren’t. Although they both involved using MRI technology to watch what someone’s brain does while they read, this one from scientists in England was looking at how the brain translates markings on paper into meaningful words, while this study from the University of California, Berkley compared the brain activity in subjects who read and listened to specific stories. The most conclusive finding from that particular study was that, from a neurological perspective, listening to audiobooks or podcasts is essentially equivalent to reading with your eyes, which almost seems to contradict the England study, which obviously showed that visual processing is the first neurological step in reading. That’s not really a contradiction, though, when you stop to think about just how busy the brain is when reading.
Neurologists have always known that reading is a complex cognitive process that doesn’t have its own designated brain region; it requires cooperation between several different cognitive processes, including those that process visual input, those that relate to spoken language, and higher-order thinking. (That is, our conscious thoughts) But these recent studies have given neurologists a clearer map of written language’s path through the brain. Both of these studies also indicate that the exact brain activity varies slightly depending upon what the participant is reading. In fact, in the study from the University of California, researchers could predict what words the person was reading based upon brain activity. It would seem that our brains associate words with each other based both upon how that word is pronounced and what it means. These studies have some very useful potential applications, such as helping people with dyslexia or auditory processing disorders. In the meantime, they provide us with a couple new fun facts. As far as I’m concerned, fun facts are pretty important, too.

 This leads me to some other interesting information about language and linguistics. The Max Planck Institute for Psycholinguistics suggests that the complexity of the grammar in any particular language is determined by the population size of the group in which the language developed. (That is, languages with more speakers have simpler grammatical rules) This isn’t a new theory, in fact, it’s fairly well established that there’s a correlation between a language’s simplicity and its current population of speakers.
This leads me to some other interesting information about language and linguistics. The Max Planck Institute for Psycholinguistics suggests that the complexity of the grammar in any particular language is determined by the population size of the group in which the language developed. (That is, languages with more speakers have simpler grammatical rules) This isn’t a new theory, in fact, it’s fairly well established that there’s a correlation between a language’s simplicity and its current population of speakers.  This research from Princeton University
This research from Princeton University The other rule has to do with variety. If you show a child a picture of three different kinds of dogs and teach the child that those are called dogs, the child will easily understand that dogs come in a variety of sizes and appearances. But if you showed the same child a picture of three dalmatians and teach them the word dog, that child might think that only a dalmatian is a “dog”. In real life, I would imagine that this applies across a period of time. If the child learns that a certain dalmatian is a “dog” one day and then learns that a certain dachshund is a “dog” a few days later, and then later hears Grandma call her golden retriever a “dog”, that child will understand that “dog” is a general word that encompasses many animals. But if the child doesn’t know any dogs other than Grandma’s golden retriever, he or she may not recognize a dalmation or a dachshund as a dog for months or even years after learning the word “dog”.
The other rule has to do with variety. If you show a child a picture of three different kinds of dogs and teach the child that those are called dogs, the child will easily understand that dogs come in a variety of sizes and appearances. But if you showed the same child a picture of three dalmatians and teach them the word dog, that child might think that only a dalmatian is a “dog”. In real life, I would imagine that this applies across a period of time. If the child learns that a certain dalmatian is a “dog” one day and then learns that a certain dachshund is a “dog” a few days later, and then later hears Grandma call her golden retriever a “dog”, that child will understand that “dog” is a general word that encompasses many animals. But if the child doesn’t know any dogs other than Grandma’s golden retriever, he or she may not recognize a dalmation or a dachshund as a dog for months or even years after learning the word “dog”.  The University of Illinois at Urbana-Champaign has conducted another recent study
The University of Illinois at Urbana-Champaign has conducted another recent study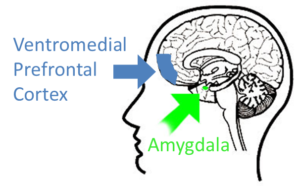 This recent research demonstrates that this creepy feeling comes from the ventromedial prefrontal cortex, (VMPFC) the brain region that is essentially right behind your eyes. This is not surprising because the roles of the VMPFC have to do with processing fear, evaluating risks, and making decisions. The VMPFC regulates the fight-or-flight reaction generated in another brain region called the amygdala. If you walk into a dimly lit room and see a spooky face staring at you, it’s your amygdala that’s responsible for that immediate, instinctive moment of panic. You feel a jolt of fear, your heart rate suddenly goes up, you probably physically draw back… and then you realize that there’s a mirror on the wall. The spooky face is your own reflection, and it only looks spooky because of the dim lighting. You can thank your VMPFC for assessing the situation and figuring out that there’s no legitimate danger before you had a chance to act on that fight-or-flight response and run away from your own reflection like an idiot.
This recent research demonstrates that this creepy feeling comes from the ventromedial prefrontal cortex, (VMPFC) the brain region that is essentially right behind your eyes. This is not surprising because the roles of the VMPFC have to do with processing fear, evaluating risks, and making decisions. The VMPFC regulates the fight-or-flight reaction generated in another brain region called the amygdala. If you walk into a dimly lit room and see a spooky face staring at you, it’s your amygdala that’s responsible for that immediate, instinctive moment of panic. You feel a jolt of fear, your heart rate suddenly goes up, you probably physically draw back… and then you realize that there’s a mirror on the wall. The spooky face is your own reflection, and it only looks spooky because of the dim lighting. You can thank your VMPFC for assessing the situation and figuring out that there’s no legitimate danger before you had a chance to act on that fight-or-flight response and run away from your own reflection like an idiot.  All of this is to say that it stands to reason that the VMPFC is the brain region responsible for generating the general feeling of unease described by the uncanny valley. If you’re having a conversation with a machine that has artificial intelligence and a human-like appearance, you’re not in immediate, obvious, physical danger. Unless you’ve previously had some kind of traumatic experience with AI-endued robots, your amygdala will probably not be generating the kind of fear that makes you want to run away screaming. But the situation is bizarre enough that your VMPFC remains wary. It’s anticipating the possibility of risks and decisions that require conscious thought rather than instinctive action. And that anticipation translates to what is best described as a creepy feeling.
All of this is to say that it stands to reason that the VMPFC is the brain region responsible for generating the general feeling of unease described by the uncanny valley. If you’re having a conversation with a machine that has artificial intelligence and a human-like appearance, you’re not in immediate, obvious, physical danger. Unless you’ve previously had some kind of traumatic experience with AI-endued robots, your amygdala will probably not be generating the kind of fear that makes you want to run away screaming. But the situation is bizarre enough that your VMPFC remains wary. It’s anticipating the possibility of risks and decisions that require conscious thought rather than instinctive action. And that anticipation translates to what is best described as a creepy feeling. 

 Meanwhile, for adults, coffee could help fight obesity
Meanwhile, for adults, coffee could help fight obesity Rather than ending on that bleak note, I’ll wrap this up by pointing out an impressive technological feat. Researchers from Carnegie Mellon University have developed a brain-controlled robotic arm that’s headline-worthy as the least-invasive BCI yet. BCI stands for Brain Computer Interface, and it’s basically what it sounds like. The technology actually exists for computers to respond directly to the human brain. I have no idea how it works.
Rather than ending on that bleak note, I’ll wrap this up by pointing out an impressive technological feat. Researchers from Carnegie Mellon University have developed a brain-controlled robotic arm that’s headline-worthy as the least-invasive BCI yet. BCI stands for Brain Computer Interface, and it’s basically what it sounds like. The technology actually exists for computers to respond directly to the human brain. I have no idea how it works.  Meanwhile, the University of Edinburgh has been asking the big questions and perfecting the chocolate-making process
Meanwhile, the University of Edinburgh has been asking the big questions and perfecting the chocolate-making process
 But speaking of small children,
But speaking of small children, Here’s another story about genetics,
Here’s another story about genetics, The biggest science news of April 2019 is a picture of a fuzzy orange circle against a black background. It’s been around for more than a month now, so the h
The biggest science news of April 2019 is a picture of a fuzzy orange circle against a black background. It’s been around for more than a month now, so the h People have been noticing for a while that the “Mediterranean diet” seems to be healthier than the “Western diet”. Although there are some organizations out there that have put forth very specific definitions of what constitutes the “Mediterranean diet,” the basic gist is that American food includes more animal-based fats, whereas the cuisine in places like Greece and southern Italy has more plant-based fats, especially olive oil. Proponents of the Mediterranean diet often point out the significance of cultural factors beyond nutrition. Our eating habits in America tend to prioritize convenience over socialization, while the idyllic Mediterranean meal is home-cooked, shared with family and friends, eaten at a leisurely pace, and most likely enjoyed with a glass or two of wine. I mention this because
People have been noticing for a while that the “Mediterranean diet” seems to be healthier than the “Western diet”. Although there are some organizations out there that have put forth very specific definitions of what constitutes the “Mediterranean diet,” the basic gist is that American food includes more animal-based fats, whereas the cuisine in places like Greece and southern Italy has more plant-based fats, especially olive oil. Proponents of the Mediterranean diet often point out the significance of cultural factors beyond nutrition. Our eating habits in America tend to prioritize convenience over socialization, while the idyllic Mediterranean meal is home-cooked, shared with family and friends, eaten at a leisurely pace, and most likely enjoyed with a glass or two of wine. I mention this because  Let’s move on from foods to beverages. Scientists have suggested that taste preferences could be genetic, and
Let’s move on from foods to beverages. Scientists have suggested that taste preferences could be genetic, and  All of this neuroscience stuff makes me think of
All of this neuroscience stuff makes me think of  The uncanny valley refers to the creepy feeling that people get from something non-human that seems very humanlike. For example, robots with realistic faces and voices are very unsettling. If you don’t know what I mean, look up Erica from the Intelligent Robotics Laboratory at Osaka University. Or just Google “uncanny valley” and you’ll easily find plenty of examples. Although the concept of the uncanny valley generally refers to humanoid robots, the same thing is true of other things, like realistic dolls or shadows that seem human-shaped. It’s why most people actually find clowns more creepy than funny, and it’s one of several reasons that it’s disturbing to see a dead body. The term “uncanny valley” refers to the shape of a graph that estimates the relationship between something’s human likeness and the degree to which it feels unsettling. Up to a certain point, things like robots or dolls are more appealing if they’re more human-like, but then there’s a steep “valley” in the graph where the thing in question is very human-like and very unappealing. This tweeted picture of non-things isn’t quite the same thing because it doesn’t involve human likeness. But there’s still something intrinsically unsettling about an image that looks more realistic at a glance than it does when you look more closely.
The uncanny valley refers to the creepy feeling that people get from something non-human that seems very humanlike. For example, robots with realistic faces and voices are very unsettling. If you don’t know what I mean, look up Erica from the Intelligent Robotics Laboratory at Osaka University. Or just Google “uncanny valley” and you’ll easily find plenty of examples. Although the concept of the uncanny valley generally refers to humanoid robots, the same thing is true of other things, like realistic dolls or shadows that seem human-shaped. It’s why most people actually find clowns more creepy than funny, and it’s one of several reasons that it’s disturbing to see a dead body. The term “uncanny valley” refers to the shape of a graph that estimates the relationship between something’s human likeness and the degree to which it feels unsettling. Up to a certain point, things like robots or dolls are more appealing if they’re more human-like, but then there’s a steep “valley” in the graph where the thing in question is very human-like and very unappealing. This tweeted picture of non-things isn’t quite the same thing because it doesn’t involve human likeness. But there’s still something intrinsically unsettling about an image that looks more realistic at a glance than it does when you look more closely.  Every few months, it seems that the people of social media collectively rediscover their love for the Myers-Briggs model of personality types. One day, people are posting about politics and television shows and kittens, and then suddenly the next day, it’s all about why life is hard for INTPs or 18 things you’ll only understand if you’re an ESTJ. (I, for the record, am apparently an INFJ) There’s just something about the Myers-Briggs Type Indicator that is fun, interesting, and at least seems to be extremely helpful. For all of the critical things that I’m about to say about it, I admittedly still try the quizzes and read the articles and find it all very interesting. I don’t think it’s total nonsense, even if it isn’t quite as informative as many people think. I should also acknowledge that there’s some difference between the quick internet quizzes and the official MBTI personality assessment instrument, which should be administered by a certified professional and will cost some money. However, the internet quizzes use the same personality model with all the same terminology, and they usually work in a similar way, so I think it’s fair to treat the quiz results as a pretty good guess of your official MBTI personality type.
Every few months, it seems that the people of social media collectively rediscover their love for the Myers-Briggs model of personality types. One day, people are posting about politics and television shows and kittens, and then suddenly the next day, it’s all about why life is hard for INTPs or 18 things you’ll only understand if you’re an ESTJ. (I, for the record, am apparently an INFJ) There’s just something about the Myers-Briggs Type Indicator that is fun, interesting, and at least seems to be extremely helpful. For all of the critical things that I’m about to say about it, I admittedly still try the quizzes and read the articles and find it all very interesting. I don’t think it’s total nonsense, even if it isn’t quite as informative as many people think. I should also acknowledge that there’s some difference between the quick internet quizzes and the official MBTI personality assessment instrument, which should be administered by a certified professional and will cost some money. However, the internet quizzes use the same personality model with all the same terminology, and they usually work in a similar way, so I think it’s fair to treat the quiz results as a pretty good guess of your official MBTI personality type. Before editing this blog post, I had a paragraph here in which I got sarcastic about the concept that “knowing” yourself is the answer to everything. That was an unnecessarily lengthy tangent, but the point remains that the appeal of personality type models is the perceived promise of practical applications. It stands to reason that self-knowledge means recognizing your strengths and weaknesses, learning to make the right decisions for your own life, and improving your ability to communicate with others, especially if you know their personality types as well. Once you know what category you belong in, you can find personalized guidelines for all of these things.
Before editing this blog post, I had a paragraph here in which I got sarcastic about the concept that “knowing” yourself is the answer to everything. That was an unnecessarily lengthy tangent, but the point remains that the appeal of personality type models is the perceived promise of practical applications. It stands to reason that self-knowledge means recognizing your strengths and weaknesses, learning to make the right decisions for your own life, and improving your ability to communicate with others, especially if you know their personality types as well. Once you know what category you belong in, you can find personalized guidelines for all of these things. As a quick Google search can inform you, the Myers-Briggs Type Indicator was created by a mother/daughter team (Katherine Cook Briggs and Isabel Briggs Myers) and based largely upon their subjective observations. Upon discovering the works of pioneering psychologist Carl Jung in the 1920s, they essentially blended his theories with their own. The MBTI as we know it today was created in the 1940s and reached the awareness of the general public when Isabel Myers self-published a short book on it in 1962.
As a quick Google search can inform you, the Myers-Briggs Type Indicator was created by a mother/daughter team (Katherine Cook Briggs and Isabel Briggs Myers) and based largely upon their subjective observations. Upon discovering the works of pioneering psychologist Carl Jung in the 1920s, they essentially blended his theories with their own. The MBTI as we know it today was created in the 1940s and reached the awareness of the general public when Isabel Myers self-published a short book on it in 1962.
 The “Big Five” personality traits are called Openness, Conscientiousness, Extroversion, Agreeableness, and Neuroticism. (When I first read about this, they were ordered differently. I suspect they were rearranged specifically for the sake of the OCEAN acronym.) Each is a spectrum rather than a dichotomy as in the Myers-Briggs model. For example, I’m high on the Conscientiousness, Agreeableness, and Neuroticism scales, but in the middle on Openness and very low on Extroversion. I’ve seen multiple internet articles that describe this model completely inaccurately, so I want to stress that there are five factors, not five personality types. The Five-Factor Model doesn’t sort people into just a few categories the way the MBTI does because it acknowledges a middle ground. Depending upon which questionnaire you use, your results for each of the five factors might be numbers on a scale between 1 and 100, or they might be phrased as “very high”, “high”, “average”, “low” or “very low”. Either way, your personality includes a ranking on each of these five factors. This is one of the things I like about the Five-Factor Model. The stark dichotomies of the Myers-Briggs model might be convenient for categorizing people, but they sure don’t accurately portray the nature of personality.
The “Big Five” personality traits are called Openness, Conscientiousness, Extroversion, Agreeableness, and Neuroticism. (When I first read about this, they were ordered differently. I suspect they were rearranged specifically for the sake of the OCEAN acronym.) Each is a spectrum rather than a dichotomy as in the Myers-Briggs model. For example, I’m high on the Conscientiousness, Agreeableness, and Neuroticism scales, but in the middle on Openness and very low on Extroversion. I’ve seen multiple internet articles that describe this model completely inaccurately, so I want to stress that there are five factors, not five personality types. The Five-Factor Model doesn’t sort people into just a few categories the way the MBTI does because it acknowledges a middle ground. Depending upon which questionnaire you use, your results for each of the five factors might be numbers on a scale between 1 and 100, or they might be phrased as “very high”, “high”, “average”, “low” or “very low”. Either way, your personality includes a ranking on each of these five factors. This is one of the things I like about the Five-Factor Model. The stark dichotomies of the Myers-Briggs model might be convenient for categorizing people, but they sure don’t accurately portray the nature of personality. There’s concern that even the Five-Factor Model is too subjective and unscientific. It’s based on the lexical hypothesis, which is the concept that personality is so central to the human experience that any language will necessarily develop the terminology to accurately describe and define it; therefore, making lists of words is a perfectly reliable and objective starting place for analyzing personality traits. While I personally find that idea fascinating and very plausible, it obviously leaves some room for doubt and criticism. Does language really reflect the nature of humanity so accurately and thoroughly that we can rely on linguistics to discover truths about psychology? Maybe, but it’s not very scientific to assume so.
There’s concern that even the Five-Factor Model is too subjective and unscientific. It’s based on the lexical hypothesis, which is the concept that personality is so central to the human experience that any language will necessarily develop the terminology to accurately describe and define it; therefore, making lists of words is a perfectly reliable and objective starting place for analyzing personality traits. While I personally find that idea fascinating and very plausible, it obviously leaves some room for doubt and criticism. Does language really reflect the nature of humanity so accurately and thoroughly that we can rely on linguistics to discover truths about psychology? Maybe, but it’s not very scientific to assume so. I’ve seen some articles that do claim that the Myers-Briggs Type Indicator is evidence-based, but so far, I can’t find any actual research cited. I expect that there probably has been some research done at some point, but nothing that shows beyond a doubt that a person’s Myers-Briggs personality type is useful for predicting behavior, analyzing strengths and weaknesses, or making decisions. The skeptics who compare the MBTI to astrology are not entirely wrong. Personally, my expectation is that any kind of objective analysis would indeed validate the idea that there are different personality types, and that a person’s personality type has some correlation to their behaviors or cognitive patterns, but that the correlations won’t be as strong as people would expect, and that the Myers-Briggs would prove to be less precise than other models based on factor analysis. I’m looking forward to the further developments that are sure to come along soon now that we’re seeing such advances in neuroscience.
I’ve seen some articles that do claim that the Myers-Briggs Type Indicator is evidence-based, but so far, I can’t find any actual research cited. I expect that there probably has been some research done at some point, but nothing that shows beyond a doubt that a person’s Myers-Briggs personality type is useful for predicting behavior, analyzing strengths and weaknesses, or making decisions. The skeptics who compare the MBTI to astrology are not entirely wrong. Personally, my expectation is that any kind of objective analysis would indeed validate the idea that there are different personality types, and that a person’s personality type has some correlation to their behaviors or cognitive patterns, but that the correlations won’t be as strong as people would expect, and that the Myers-Briggs would prove to be less precise than other models based on factor analysis. I’m looking forward to the further developments that are sure to come along soon now that we’re seeing such advances in neuroscience.












